搜索引擎爬虫抓取我们的网页,是实现SEO优化工作的第一步。如果没有抓取,网站就不会被搜索引擎收录,那也不会有排名了。所以针对每一个为SEO从业者,抓取是第一步!

实际上,大多数SEO从业者知道的搜索引擎抓取算法只有深度优先和宽度优先抓取两个策略。但实际不然,爬虫抓取的网页的策略有5个。
我们先来看下百度蜘蛛(搜索引擎)的工作流程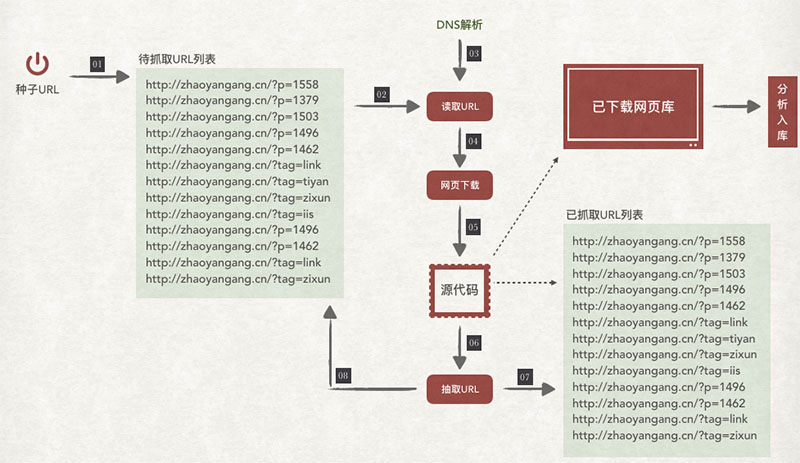
所谓种子URL所指的就是最开始选定的URL地址,大多数情况下,网站的首页、频道页等丰富性内容更多的页面会被作为种子URL;
然后将这些种子URL放入到待抓取的URL列表中;
爬虫从待抓取的URL列表中逐个进行读取,读取URL的过程中,会将URL通过DNS解析,把这个URL地址转换成网站服务器的IP地址+相对路径的方式;
接下来把这个地址交给网页下载器(所谓网页下载器,顾名思义就是负责下载网页内容的一个模块);
对于下载到本地的网页,也就是我们网页的源代码,一方面要将这个网页存储到网页库中,另一方面会从下载网页中再次提取URL地址。
新提取出来的URL地址会先在已抓取的URL列表中进行比对,检查一下这个网页是不是被抓取了。
如果网页没有被抓取,就将新的URL地址放入到待抓取的URL列表的末尾,等待被抓取。
就这样循环的工作着,直到待抓取队列为空的时候,爬虫就算完成了抓取的全过程。
然后以下载的网页,就都会进入到一定的分析中,分析后进行索引,我们就能看到收录结果了。
对于真正的爬虫来说,先抓哪些页面、后抓哪些页面,以及不抓哪些页面等等都是有一定的策略的,这里讲述的是一个比较通过、普遍的爬虫抓取流程,身为SEO的我们,知道这些足以。
宽度优先抓取策略,一个历史悠久且一直被关注的抓取策略,从搜索引擎爬虫诞生至今一直被使用的抓取策略,甚至很多新的策略也是通过这个作为基准的。
宽度优先抓取策略是通过待抓取URL列表为基准进行抓取,发现的新链接,且判断为未抓取过的基本就直接存放到待抓取URL列表的末尾,等待抓取。
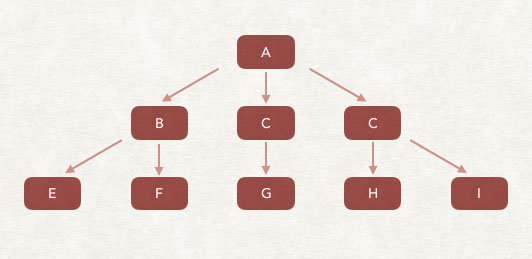
如上图,我们假设爬虫的待抓取URL列表中,只有A,爬虫从A网页开始抓取,从A中提取了B、C、D网页,于是将B、C、D放入到抓取队列,再依次获得E、F、G、H、I网页并插入到待抓取的URL列表中,以此类推,周而复始。
深度优先抓取的策略是爬虫会从待抓取列表中抓取第一个URL,然后沿着这个URL持续抓取这个页面的其他URL,直到处理完这个线路后,再从待抓取的列表中,抓取第二个,以此类推。下面给了一个图解。
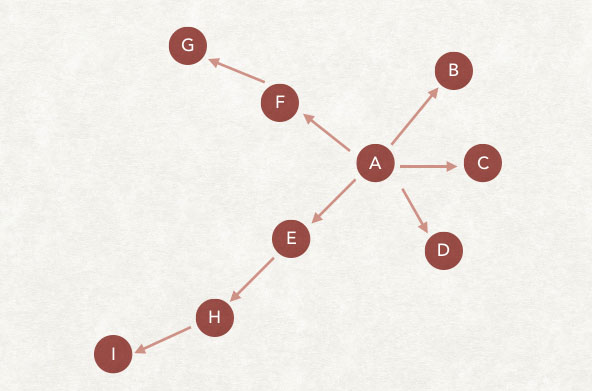
A作为第一个从待抓取列表的URL,爬虫开始抓取,然后抓取到B、C、D、E、F,但B、C、D中都没有后续的链接了(这里也是会去掉已经抓取过的页面),从E中发现了H,顺着H,发现了I,然后就没有更多了。在F中发现了G,然后针对这个链接的抓取就结束了。从待抓取列表中,拿到下一个链接继续上述操作。
相信PageRank算法很多人都知道,我们SEO的大白话理解就是链接传递权重的算法。而如果应用在爬虫抓取上,是怎样的逻辑呢?首先爬虫的目的是去下载网页,与此同时爬虫不能看到所有的网页指向某一网页的链接,所以在抓取的过程中,爬虫是无法计算全部网页的pagerank的,就导致了在抓取过程中计算的pagerank不是太靠谱。
那非完全pagerank抓取策略,就是基于在爬虫不能看到所有网页指向某一网页的链接,而只能看到部分的情况,还要进行pagerank的计算结果。
它的具体策略就是对已经下载了的网页,加上待抓取的URL列表里的网页一起,形成一个汇总。在这个汇总内进行pagerank的计算。在计算完成后,待抓取的url列表里的每一个url都会得到一个pagerank值,然后按照这个值进行倒序排列。先抓取pagerank分值最高的,然后逐个抓取。
那问题来了?待抓取URL列表中,在末尾新增一个URL,就要重新计算一次吗?
实际不是这样的。搜索引擎会等到在待抓取URL列表的新增URL达到一定数量时,再进行重新抓取。这样效率会提升很多。毕竟爬虫抓取到新增的那第一个,也需要时间的。
OPIC是online page importance computation的缩写,意思是“在线页面重要性计算”,这个是pagerank的升级版本。
它具体的策略逻辑是这样,爬虫把互联网上所有的URL都赋予一个初始的分值,且每个URL都是同等的分值。每当下载一个网页就把这个网页的分值平均分摊给这个页面内的所有链接。自然这个页面的分值就要被清空了。而对于待抓取的URL列表里(当然,刚才那个网页被清空了分值,也是因为它已经被抓取了),则根据谁的分值最高就优先抓取谁。
区别于pagerank,opic是实时计算的。这里提醒我们,如果单纯只考虑opic这个抓取策略来说。无论是这个策略还是pagerank策略都证实了一个逻辑。我们新产生的网页,被链接的次数越多,被抓取的概率就越大。
是不是值得你思考一下你的网页布局了?
大站优先抓取,是不是就顾名思义了呢?大型网站就会有先抓取?不过这里是有两种解释的。我个人认为这两种解释爬虫都在使用。
大站优先抓取的解释1:比较贴合字面意思,爬虫会根据待抓取列表中的URL进行归类,然后判断域名对应的网站级别。例如权重越高的网站所属域名越应该优先抓取。
大站优先抓取解释2:爬虫将待抓取列表里的URL按照域名进行归类,然后计算数量。其所属域名在待抓取列表里数量最多的优先抓取。
这两个解释一个是针对网站权重高的,一个是针对每天文章发布数量高且发布很集中的。不过我们试想一下,发布那么集中且那么多篇的站点,一般也都是大站了吧?
这里让我们思考的是什么呢?
写文章的同时,应该集中一个时间点推送给搜索引擎。不能一个小时一篇,太分散。不过这个有待考证,有经历的同学可以进行一下测试。